Week 1: ML Strategy (1)
What is machine learning strategy? Lets start with a motivating example.
Introduction to ML strategy
Why ML strategy
Lets say you are working on a cat classifier. You have achieved 90% accuracy, but would like to improve performance even further. Your ideas for achieveing this are:
- collect more data
- collect more diverse training set
- train the algorithm longer with gradient descent
- try adam (or other optimizers) instead of gradient descent
- try dropout, add L2 regularization, change network architecture, ...
This list is long, and so it becomes incredibly important to be able to identify ideas that are worth our time, and which ones we can likely discard.
This course will attempt to introduce a framework for making these decisions. In particular, we will focus on the organization of deep learning-based projects.
Orthogonalization
One of the challenges with building deep learning systems is the number of things we can tune to improve performance (many hyperparameters notwithstanding).
Take the example of an old TV. They included many nobs for tuning the display position (x-axis position, y-axis position, rotation, etc...).
Orthogonalization in this example refers to the TV designers decision to ensure each nob had one effect on the display and that these effects were relative to one another. If these nobs did more than one action and each actions magnitude was not relative to the other, it would become nearly impossible to tune the TV.
Take another example, driving a car. Imagine if there was multiple joysticks. One joystick modified \(0.3\) X steering angle \(- 0.8\) speed, and another \(2\) X steering angle \(+ 0.9\) speed. In theory, by tuning these two nobs we could drive the car, but this would be much more difficult then separating the inputs into distinct input mechanisms.
Orthogonal refers to the idea that the inputs are aligned to the dimensions we want to control.

How does this related to machine learning?
Chain of assumption in examples
For a machine learning system to perform "well", we usually aim to make four things happen:
- Fit training set well on cost function (for some applications, this means comparing favorably to human-level performance).
- Fit dev set well on cost function
- Fit test set well on cost function
- Performs well in real world.
If we relate back to the TV example, we wanted one knob to change each attribute of the display. In the same way, we can modify knobs for each of our four steps above:
- Train a bigger network, change the optimization algorithm, ...
- Regularization, bigger training set, ...
- Bigger dev set, ...
- Change the dev set or the cost function
Note
Andrew said when he trains neural networks, he tends not to use early stopping. The reason being is that this is not a very orthogonal "knob"; it simultaneously effects how well we fit the training set and the dev set.
The whole idea here is that if we keep our "knobs" orthogonal, we can more easily come up with solutions to specific problems with our deep neural networks (i.e., if we are getting poor performance on the training set, we may opt to train a bigger [higher variance] network).
Setting up your goal
Single number evaluation metric
When tuning neural networks (modifying hyper-parameters, trying different architectures, etc.) you will find that having a _single __evaluation metric___ will allow you to easily and quickly judge if a certain change improved performance.
Note
Andrew recommends deciding on a single, real-valued evaluation metric when starting out on your deep learning project.
Lets look at an example.
As we discussed previously, applied machine learning is a very empirical process.
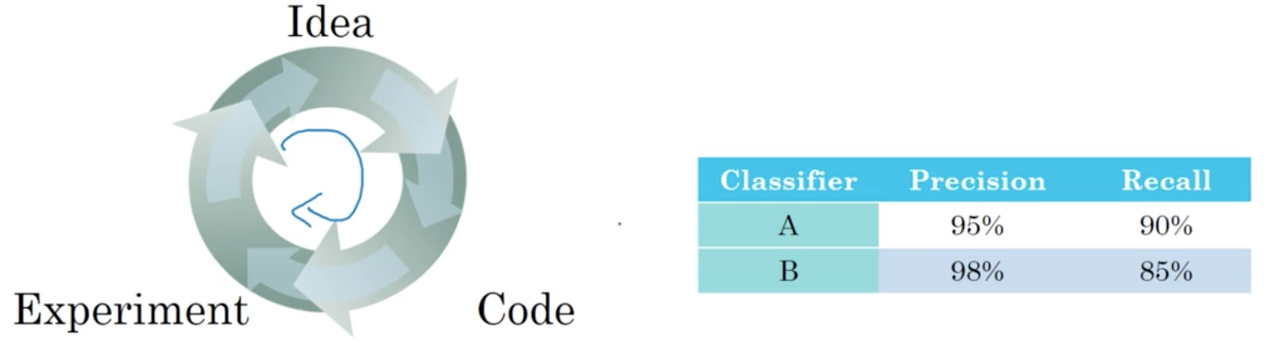
Lets say that we start with classifier A, and end up with classifier B after some change to the model. We could look at precision and recall as a means of improvements. What we really want is to improve both precision and recall. The problem is that it can become difficult to choose the "best" classifier if we are monitoring two different performance metrics, especially when we are making many modifications to our network.
This is when it becomes important to chose a single performance metric. In this case specifically, we can chose the F1-score, the harmonic mean of the precision and recall (less formally, think of this as an average).

We can see very quickly that classifier A has a better F1-score, and therefore we chose classifier A over classifier B.
Satisficing and Optimizing metric
It is not always easy to combine all the metrics we care about into a single real-numbered value. Lets introduce satisficing and optimizing metrics as a solution to this problem.
Lets say we are building a classifier, and we care about both our accuracy (measured as F1-score, traditional accuracy or some other metric) and the running time to classify a new example.
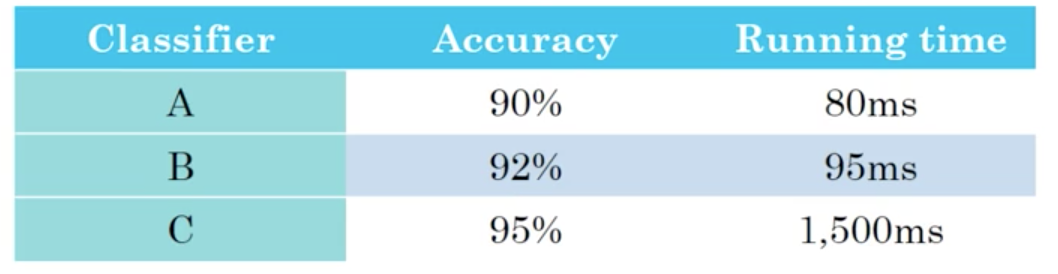
One thing we can do, is to combine accuracy and run-time into a single-metric, possibly by taking a weighted linear sum of the two metrics.
Note
As it turns out, this tends to produce a rather artificial solution (no pun intended).
Another way, is to attempt to maximize accuracy while subject to the restraint that \(\text{running time} \le 100\)ms. In this case, we say that accuracy is an optimizing metric (because we want to maximize or minimize it) and running time is a satisficing metric (because it just needs to meet a certain constraint, i.e., be "good enough").
More generally, if we have \(m\) metrics that we care about, it is reasonable to choose one to be our optimizing metric, and \(m-1\) to be satisficing metrics.
Example: Wake words
We can take a concrete example to illustrate this: wake words for intelligent voice assistants. We might chose the accuracy of the model (i.e., what percent of the time does it "wake" when a wake word is said) to be out optimizing metric s.t. we have \(\le 1\) false-positives per 24 hours of operation (our satisficing metric).
Summary
To summarize, if there are multiple things you care about, we can set one as the optimizing metric that you want to do as well as possible on and one or more as satisficing metrics were you'll be satisfied. This idea goes hand-in-hand with the idea of having a single real-valued performance metric whereby we can quickly and easily chose the best model given a selection of models.
Train/dev/test distributions
The way you set up your train, dev (sometimes called valid) and test sets can have a large impact on your development times and even model performance.
In this video, we are going to focus on the dev (sometimes called the valid or hold out set) and the test set. The general workflow in machine learning is to train on the train set and test out model performance (e.g., different hyper-parameters or model architectures) on the dev set.
Lets look at an example. Say we had data from multiple regions:
- US
- UK
- Other European countries
- South America
- India
- China
- Other Asian countries
- Australia
If we were to build our dev set by choosing data from the first four regions and our test set from the last four regions, our data would likely be skewed and our model would likely perform poorly (at least on the test set). Why?
Imagine the dev set as a target, and our job as machine learning engineers is to hit a bullseye. A dev set that is not representative of the overall general distribution is analogous to moving the bullseye away from its original location moments after we fire our bow. An ML team could spend months optimizing the model on a dev set, only to achieve very poor performance on a test set!
So for our data above, a much better idea would be to sample data randomly from all regions to build our dev and test set.
Guidelines
Choose a dev set and test set (from the same distribution) to reflect data you expect to get in the future and consider important to do well on.
Size of the dev and test sets
In the last lecture we saw that the dev and test sets should come from the same distributions. But how large should they be?
Size of the dev/test sets
The rule of thumb in machine learning is typically 60% training, 20% dev, and 20% test (or 70/30 train/test). In earlier eras of machine learning, this was pretty reasonable. In the modern machine learning era, we are used to working with much larger data set sizes.
For example, imagine we have \(1,000,000\) examples. It might be totally reasonable for us to use 98% as our test set, 1% for dev and 1% for test.
Note
Note that 1% of \(10^6\) is \(10^4\)!
Guidelines
Set your test set to be big enough to give high confidence in the overall performance of your system.
When to change dev/test sets and metrics
Sometimes during the course of a machine learning project, you will realize that you want to change your evaluation metric (i.e., move the "goal posts"). Lets illustrate this with an example:
Example 1
Imagine we have two models for image classification, and we are using classification performance as our evaluation metric:
- Algorithm A has a 3% error, but sometimes shows users pornographic images.
- Algorithm B has a 5% error.
Cleary, algorithm A performs better by our original evaluation metric (classification performance), but showing users pornographic images is unacceptable.
\[Error = \frac{1}{m_{dev}}\sum^{m_{dev}}{i=1} \ell { y{pred}^{(i)} \ne y^{(i)} }\]
Note
Our error treats all incorrect predictions the same, pornographic or otherwise.
We can think of it like this: our evaluation metric prefers algorithm A, but we (and our users) prefer algorithm B. When our evaluation metric is no longer ranking the algorithms in the order we would like, it is a sign that we may want to change our evaluation metric. In our specific example, we could solve this by weighting misclassifications
\[Error = \frac{1}{w^{(i)}}\sum^{m_{dev}}{i=1} w^{(i)}\ell { y{pred}^{(i)} \ne y^{(i)} }\]
where \(w^{(i)}\) is 1 if \(x^{(i)}\) is non-porn and 10 (or even 100 or larger) if \(x^{(i)}\) is porn.
This is actually an example of orthogonalization. We,
- Define a metric to evaluate our model ("placing the target")
- (In a completely separate step) Worry about how to do well on this metric.
Example 2
Take the same example as above, but with a new twist. Say we train our classifier on a data set of high quality images. Then, when we deploy our model we notice it performs poorly. We narrow the problem down to the low quality images users are "feeding" to the model. What do we do?
In general: if doing well on your metric + dev/test set does not correspond to doing well on your application, change your metric and/or dev/test set.
Comparing to human-level performance
In the last few years, comparing machine learning systems to human level performance have become common place. The reasons for this include:
- Deep learning based approaches are making extraordinary gains in performance, so our baseline needs to be more stringent.
- Many of the tasks deep learning is performing well at were thought to be very difficult for machines (e.g. NLP, computer vision). Comparing performance on these tasks to a human baseline is natural.
It is also instructive to look at the performance of machine learning over time (note this is an obvious abstraction)
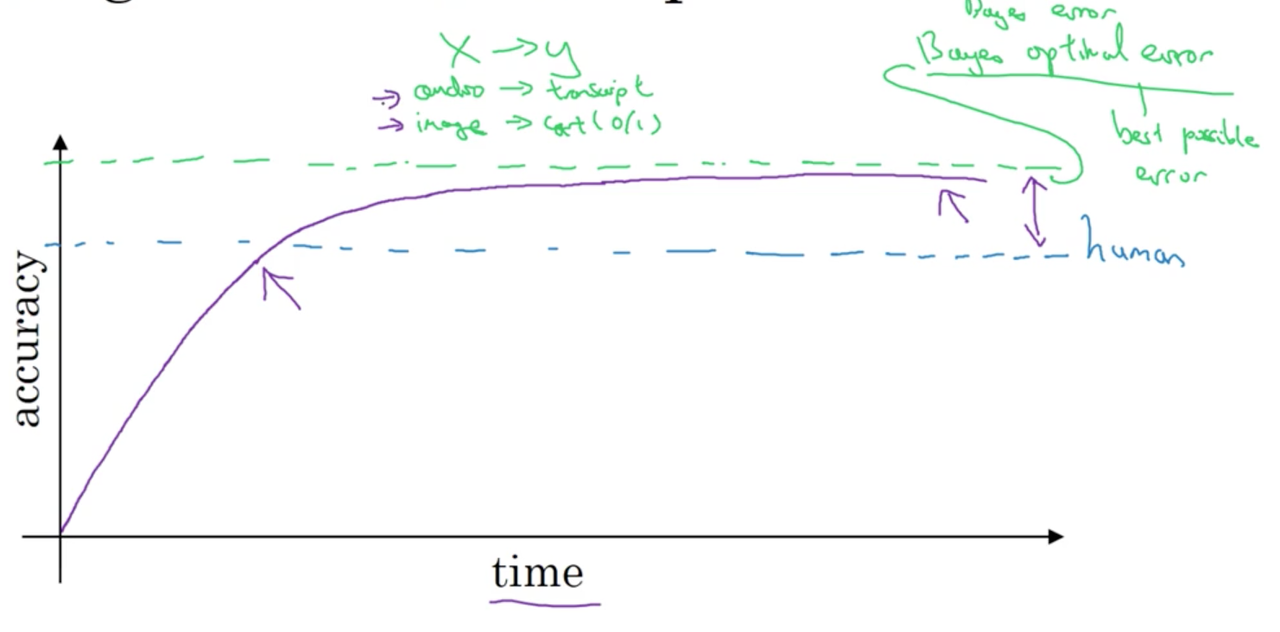
Roughly speaking, performance (e.g., in a research domain or for a certain task) progresses quickly until we reach human-level performance, and tails off quickly. Why? mainly because human level performance is typically very close to the Bayes optimal error. Bayes optimal error is the best possible error; there is no way for any function mapping from \(x \rightarrow y\) to do any better. A second reason is that so long as ML performs worse than humans for a given task, we can:
- get labeled data from humans
- gain insight from manual error analysis (e.g., why did a person get this right?)
- better analysis of bias/variance
Avoidable bias
Of course, we want our learning algorithm to perform well on the training set, but not too well. Knowing where human level performance is can help us decide how well we want to perform on the training set.
Let us again take the example of an image classifier. For this particular data set, assume:
- human-level performance is an error of 1%.
- our classifier is currently achieving 8% classification error on the training set and
- 10% classification on the dev set.
Clearly, it has plenty of room to improve. Specifically, we would want to try to increase variance and reduce bias.
Note
For the purposes of computer vision, assume that human-level performance \(\approx\) Bayes error.
Now, lets take the same example, but instead, we assume that human-level performance is an error of 7.5% (this example is very contrived, as humans are extremely good at image classification). In this case, we note that our classifier performances nearly as well as a human baseline. We would likely want to to decrease variance and increase bias (in order to improve performance on the dev set.)
So what did this example show us? When human-level performance (where we are using human-level performance as a proxy for Bayes error) is very high relative to our models performance on the train set, we likely want to focus on reducing "avoidable" bias (or increasing variance) in order to improve performance on the training set (e.g., by using a bigger network.) When human-level performance is comparable to our models performance on the train set, we likely want to focus on increasing bias (or decreasing variance) in order to improve performance on the dev set (e.g., by using a regularization technique or gathering more training data.)
Understanding human-level performance
The term human-level performance is used quite casually in many research articles. Lets attempt to define this term more precisely.
Recall from the last lecture that human-level performance can be used as a proxy for Bayes error. Lets revisit that idea with another example.
Suppose, for a medical image classification example,
- Typical human: 3% error
- Typical doctor: 1% error
- Experienced doctor: 0.7% error
- Team of experienced doctors: 0.5% error
What is "human-level" error? Most likely, we would say 0.5%, and thus Bayes error is \(\le 0.05%\). However, in certain contexts we may only wish to perform as well as the typical doctor (i.e., 1% error) and we may deem this "human-level error". The takeaway is that there is sometimes more than one way to determine human-level performance; which way is appropriate will depend on the context in which we expect our algorithm to be deployed. We also note that as the performance of our algorithm improves, we may decide to move the goal posts for human-level performance higher, e.g., in this example by choosing a team of experienced doctors as the baseline. This is useful for solving the problem introduced in the previous lecture: should I focus on reducing avoidable bias? or should I focus on reducing variance between by training and dev errors.
Summary
Lets summarize: if you are trying to understand bias and variance when you have a human-level performance baseline:
- Human-level error can be used as a proxy for Bayes' error
- The difference between the training error and the human-level error can be thought of as the avoidable bias.
- The difference between the training and dev errors can be thought of as variance.
- Which type of error you should focus on reducing depends on how well your model perform compares to (an estimate of) human-level error.
- As our model approaches human-level performance, it becomes harder to determine where we should focus our efforts.
Surpassing human-level performance
Surpassing human-level performance is what many teams in machine learning / deep learning are inevitably trying to do. Lets take a look at a harder example to further develop our intuition for an approach to matching or surpassing human-level performance.
- team of humans: 0.5% error
- one human: 1.0% error
- training error: 0.3% error
- dev error: 0.4% error
Notice that training error < team of humans error. Does this mean we have overfit the data by 0.2%? Or, does this means Bayes' error is actually lower than the team of humans error? We don't really know based on the information given, as to whether we should focus on bias or variance. This example is meant to illustrate that once we surpass human-level performance, it becomes much less clear how to improve performance further.
Problems where ML significantly surpasses human-level performance
Some example where ML significantly surpasses human-level performance include:
- Online advertising,
- Product recommendations
- Logistics (predicting transit time)
- Load approvals
Notice that many of these tasks are learned on structured data and do not involve natural perception tasks. This appeals to our intuition, as we know humans are excellent at natural perception tasks.
Note
We also note that these four tasks have immensely large datasets for learning.
Improving your model performance
You have heard about orthogonalization. How to set up your dev and test sets, human level performance as a proxy for Bayes's error and how to estimate your avoidable bias and variance. Let's pull it all together into a set of guidelines for how to improve the performance of your learning algorithm.
The two fundamental assumptions of supervised learning
- You can fit the training set (pretty) well, i.e., we can achieve low avoidable bias.
- The training set performance generalizes pretty well to the dev/test set, i.e., variance is not too bad.
In the spirit of orthogonalization, there are a certain set of (separate) knobs we can use to improve bias and variance. Often, the difference between the training error and Bayes error (or a human-level proxy) is often illuminating in terms of where large improvement remain to be made.
For reducing bias
- Train a bigger model
- Train longer/better optimization algorithms
- Change/tweak NN architecture/hyperparameter search.
For reducing variance
- Collect more data
- Regularization (L2, dropout, data augmentation)
- Change/tweak NN architecture/hyperparameter search.